Processing Greek corpora for the riddle solver¶

Michelangelo’s Delphic Sibyl, Sistine Chapel
Pseudo-Sibylline [1] oracles contain hexametric poems written in Ancient Greek. These oracula were mainly composed in 150BC - 700AD to twelve distinct extant books. They were circulating and quite famous among the Judaeo-Christian community at that time.
They shouldn’t, however, be too much confused with the earlier Sibylline books [2]. Sibylline books contained religious ceremonial advice that were consulted by the selected priests and curators in the Roman state when it was in deep political trouble. The collection of the original Sibylline books were destroyed by different accidental events and deliberate actions in history.
Pseudo-Sibylline oracles, on the other hand, contain Jewish narrative of the human history contrasted with the Greek mythology and to the chronology of the other great ancient empires. Another intention of the oracles was to support evolving Christian doctrine and interpretation of the prophecies. Prophecies were mostly grounded in Jewish tradition, but surprisingly some pagan world events also came to be interpreted as signs of the coming Messiah. Sibyl, the acclaimed author of the prophecies as a woman prophetess, the daughter of Noah in the Pseudo-Sibylline lore, has a unique character crossing over the common borders in several ancient religions and mythology.
Good introductions to the Pseudo-Sibylline oracles can be found from these two books:
- Sibylline Oracles in `The Old Testament Pseudepigrapha, Volume I
<https://books.google.fi/books?id=TNdeolWctsQC>`__ [3] by J. J. Collins
- Part 1 in `The Book Three of the Sibylline Oracles and Its Social Setting
<https://books.google.fi/books?id=Zqh8ZQZqnWYC>`__ [4] by Rieuwerd Buitenwerf
Focus of the study¶
Some material in the Pseudo-Sibylline oracles contains cryptic puzzles, referring to persons, cities, countries, and epithets of God for example. These secretive references are often very general in nature, pointing only to the first letter of the subject and its numerical value. Solving them requires, not so much of mathematical or cryptographical skills in a modern sense, but a proper knowledge of the context, both the inner textual and the historical context.
Most of the alphanumeric riddles in the oracles can already be taken as solved by various researchers. See footnotes in [The Sibylline Oracles](http://www.sacred-texts.com/cla/sib/sib.pdf) by Milton S. Terry for example. But, some of the riddles are still problematic and open for better proposals. Better yet, few of these open riddles are more complex and specific enough so that one may try to solve them by modern programmable tools.
As an independent researcher not affiliated with any organization, the sole motivation and purpose of mine in this book is to provide a reusable and a testable method for processing and analyzing ancient corpora, especially detecting alphanumeric patterns in a digitalized text. Although the target language in this study is Ancient Greek, the method should be applicable to any language using alphabetic numerals.
Natural language processing¶
Programmatical approach to solve the riddles requires a huge Greek text corpora. Bigger it is, the better. I will download and preprocess available open source Greek corpora, which is a quite daunting task for many reasons. Programming language of my choice is Python [5] for it has plenty of good and stable open source libraries required for my work. Python is widely recognized in academic and scientific field and well oriented to the research projects.
I have left the most of the overly technical details of these chapters for the enthusiasts to read straight from the commented code in functions.py [6] script. By collecting the large part of the used procedures to the separate script maintains this document more concise too.
In the end of the task of the first chapter, I’ll have a word database containing hundreds of thousands of unique Greek words extracted from the naturally written language corpora. Then words can be further used in the riddle solver in the second chapter.
Note
Note that rather than just reading, this, and the following chapters can also be run interactively in your local Jupyter notebook [7] installation if you prefer. That means that you may test and verify the procedure or alter parameters and try solving the riddles with your own parameters.
Your can download independent Jupyter notebooks for processing corpora [8], solving riddles [9], and analysing results [10].
You may also run code directly from Python shell environment, no problem.
Required components¶
The first sub task is to get a big raw ancient Greek text to operate with. I have implemented an importer interface with tqdm library to the Perseus [11] and the First1KGreek [12] open source data sources in this chapter.
I’m using my own Abnum [13] library to remove accents from the Greek words, remove non-alphabetical characters from the corpora, as well as calculating the isopsephical value of the Greek words. Greek accentuation [14] library is used to split words into syllables. This is required because the riddles of my closest interest contain specific information about the syllables of the words. Pandas [15] library is used as an API (application programming interface) to the collected database. Plotly [16] library and online infographic service are used for the visual presentation of the statistics.
You can install these libraries by uncommenting and running the next install lines in the Jupyter notebook:
import sys
#!{sys.executable} -m pip install tqdm abnum requests
#!{sys.executable} -m pip install pandas plotly pathlib
#!{sys.executable} -m pip install greek_accentuation
For your convenience, my environment is the following:
print("Python %s" % sys.version)
Output:
Python 3.6.1 | Anaconda 4.4.0 (64-bit) | (default, May 11 2017, 13:25:24)
[MSC v.1900 64 bit (AMD64)]
Note that Python 3.4+ is required for all examples to work properly. To find out other ways of installing PyPI maintained libraries, please consult: https://packaging.python.org/tutorials/installing-packages/
Downloading corpora¶
I’m going to use Perseus and OpenGreekAndLatin corpora for the study by combining them into a single raw text file and unique words database.
The next code snippets will download hundreds of megabytes of Greek text to a local computer for quicker access. tqdm downloader requires a stable internet connection to work properly.
One could also download source zip files via browser and place them to the same directory with the Jupyter notebook or where Python is optionally run in shell mode. Zip files must then be renamed as perseus.zip and first1k.zip.
- Download packed zip files from their GitHub repositories:
from functions import download_with_indicator, perseus_zip_file, first1k_zip_file
# download from perseus file source
fs = "https://github.com/PerseusDL/canonical-greekLit/archive/master.zip"
download_with_indicator(fs, perseus_zip_file)
# download from first1k file source
fs = "https://github.com/OpenGreekAndLatin/First1KGreek/archive/master.zip"
download_with_indicator(fs, first1k_zip_file)
Output:
Downloading: https://github.com/PerseusDL/canonical-greekLit/archive/master.zip
71.00MB [04:15, 211.08KB/s]
Downloading: https://github.com/OpenGreekAndLatin/First1KGreek/archive/master.zip
195.00MB [09:15, 201.54KB/s]
- Unzip files to the corresponding directories:
from functions import perseus_zip_dir, first1k_zip_dir, unzip
# first argument is the zip source, second is the destination directory
unzip(perseus_zip_file, perseus_zip_dir)
unzip(first1k_zip_file, first1k_zip_dir)
3. Copy only suitable Greek text xml files from perseus_zip_dir and first1k_zip_dir to the temporary work directories. Original repositories contain a lot of unnecessary files for the riddle solver which are skipped in this process.
from functions import copy_corpora, joinpaths, perseus_tmp_dir, first1k_tmp_dir
# important Greek text files resides in the data directory of the repositories
for item in [[joinpaths(perseus_zip_dir,
["canonical-greekLit-master", "data"]), perseus_tmp_dir],
[joinpaths(first1k_zip_dir,
["First1KGreek-master", "data"]), first1k_tmp_dir]]:
copy_corpora(*item)
Output:
greek_text_perseus_tmp already exists. Either remove it and run again, or
just use the old one.
Copying greek_text_first1k_tmp -> greek_text_first1k
Depending on if the files have been downloaded already, the output may differ.
Collecting files¶
When the files has been downloaded and copied, it is time to read them to the RAM (Random-Access Memory). At this point file paths are collected to the greek_corpora_x variable that is used on later iterators.
from functions import init_corpora, perseus_dir, first1k_dir
# collect files and initialize data dictionary
greek_corpora_x = init_corpora([[perseus_tmp_dir, perseus_dir], [first1k_tmp_dir, first1k_dir]])
print(len(greek_corpora_x), "files found")
Output:
1708 files found
Actual files found may differ by increasing over time, because Greek corpora repositories are constantly maintained and new texts are added by voluteer contributors.
Processing files¶
Next step is to extract Greek content from the downloaded and selected XML source files. Usually this task might take a lot of effort in NLP (natural language processing). Python NLTK [17] and CLTK [18] libraries would be useful at this point, but in my case I’m only interested of Greek words, that is, text content encoded by a certain Greek Unicode letter [19] block. Thus, I’m able to simplify this part by removing all other characters from source files except Greek characters. Again, details can be found from the functions.py script.
Extracted content is saved to the corpora/author/work based directories. Simplified uncial conversion is also made at the same time so that the final data contain only plain uppercase words separated by spaces. Pretty much in a format written by the ancient Greeks, except they didn’t even use spaces to denote individual words and phrases.

Papyrus 47, Uncial Greek text without spaces. Rev 13:17-
Next code execution will take several minutes depending on if you have already run it once and have the previous temporary directories available. Old processed corpora files are removed first, then they are recreated by calling process_greek_corpora function.
from functions import remove, all_greek_text_file, perseus_greek_text_file,\
first1k_greek_text_file, process_greek_corpora
# remove old processed temporary files
try:
remove(all_greek_text_file)
remove(perseus_greek_text_file)
remove(first1k_greek_text_file)
except OSError:
pass
# process and get greek corpora data to the RAM memory
greek_corpora = process_greek_corpora(greek_corpora_x)
Statistics¶
After the files have been downloaded and preprocessed, I’m going to output the size of them:
from functions import get_file_size
print("Size of the all raw text: %s MB" % get_file_size(all_greek_text_file))
print("Size of the perseus raw text: %s MB" % get_file_size(perseus_greek_text_file))
print("Size of the first1k raw text: %s MB" % get_file_size(first1k_greek_text_file))
Output:
Size of the all raw text: 347.76 MB
Size of the perseus raw text: 107.41 MB
Size of the first1k raw text: 240.35 MB
Then, I will calculate other statistics of the saved text files to compare their content:
from functions import get_stats
ccontent1, chars1, lwords1 = get_stats(perseus_greek_text_file)
ccontent2, chars2, lwords2 = get_stats(first1k_greek_text_file)
ccontent3, chars3, lwords3 = get_stats(all_greek_text_file)
Output:
Corpora: perseus_greek_text_files.txt
Letters: 51411752
Words in total: 9900720
Unique words: 423428
Corpora: first1k_greek_text_files.txt
Letters: 113763150
Words in total: 23084445
Unique words: 667503
Corpora: all_greek_text_files.txt
Letters: 165174902
Words in total: 32985165
Unique words: 831308
Letter statistics¶
I’m using DataFrame class from Pandas library to handle tabular data and show basic letter statistics for each corpora and combination of them. Native Counter class in Python is used to count unique elements in the given sequence. Sequence in this case is the raw Greek text stripped from all special characters and spaces, and elements are the letters of the Greek alphabet.
This will take some time to process too:
from functions import Counter, DataFrame
# perseus dataframe
df = DataFrame([[k, v] for k, v in Counter(ccontent1).items()])
df[2] = df[1].apply(lambda x: round(x*100/chars1, 2))
a = df.sort_values(1, ascending=False)
# first1k dataframe
df = DataFrame([[k, v] for k, v in Counter(ccontent2).items()])
df[2] = df[1].apply(lambda x: round(x*100/chars2, 2))
b = df.sort_values(1, ascending=False)
# perseus + first1k dataframe
df = DataFrame([[k, v] for k, v in Counter(ccontent3).items()])
df[2] = df[1].apply(lambda x: round(x*100/chars3, 2))
c = df.sort_values(1, ascending=False)
The first column is the letter, the second column is the count of the letter, and the third column is the percentage of the letter contra all letters.
from functions import display_side_by_side
# show tables side by side to save some vertical space
display_side_by_side(Perseus=a, First1K=b, Perseus_First1K=c)
Table data¶
| Perseus | FirstK1 | Both | ||||||
|---|---|---|---|---|---|---|---|---|
| Letter | Count | Percent | Letter | Count | Percent | Letter | Count | Percent |
| Α | 4182002 | 10.96 | Α | 26817705 | 10.76 | Α | 30999707 | 10.79 |
| Ε | 3678672 | 9.64 | Ο | 23687669 | 9.50 | Ο | 27351703 | 9.52 |
| Ο | 3664034 | 9.61 | Ι | 22665483 | 9.09 | Ι | 26279145 | 9.14 |
| Ι | 3613662 | 9.47 | Ε | 22498413 | 9.03 | Ε | 25909263 | 9.01 |
| Ν | 3410850 | 8.94 | Ν | 22121458 | 8.88 | Ν | 25800130 | 8.98 |
| Τ | 2903418 | 7.61 | Τ | 21698265 | 8.71 | Τ | 24601683 | 8.56 |
| Σ | 2830967 | 7.42 | Σ | 18738234 | 7.52 | Σ | 21569201 | 7.50 |
| Υ | 1776871 | 4.66 | Υ | 11384921 | 4.57 | Υ | 13161792 | 4.58 |
| Ρ | 1440852 | 3.78 | Η | 9776411 | 3.92 | Η | 11217263 | 3.90 |
| Η | 1392909 | 3.65 | Ρ | 9268111 | 3.72 | Ρ | 10661020 | 3.71 |
| Π | 1326596 | 3.48 | Κ | 8982955 | 3.60 | Κ | 10244628 | 3.56 |
| Κ | 1261673 | 3.31 | Π | 8290364 | 3.33 | Π | 9616960 | 3.35 |
| Ω | 1179566 | 3.09 | Ω | 7874161 | 3.16 | Ω | 9053727 | 3.15 |
| Μ | 1147548 | 3.01 | Μ | 7498489 | 3.01 | Μ | 1147548 | 3.01 |
| Λ | 1139510 | 2.99 | Λ | 6929170 | 2.78 | Λ | 8076718 | 2.81 |
| Δ | 932823 | 2.45 | Δ | 5757782 | 2.31 | Δ | 6690605 | 2.33 |
| Γ | 584668 | 1.53 | Γ | 4197053 | 1.68 | Γ | 4781721 | 1.66 |
| Θ | 501512 | 1.31 | Θ | 3440599 | 1.38 | Θ | 3942111 | 1.37 |
| Χ | 352579 | 0.92 | Χ | 2294905 | 0.92 | Χ | 2647484 | 0.92 |
| Φ | 325210 | 0.85 | Φ | 2115768 | 0.85 | Φ | 2440978 | 0.85 |
| Β | 220267 | 0.58 | Β | 1322737 | 0.53 | Β | 1543004 | 0.54 |
| Ξ | 152971 | 0.40 | Ξ | 951076 | 0.38 | Ξ | 1104047 | 0.38 |
| Ζ | 75946 | 0.20 | Ζ | 559728 | 0.22 | Ζ | 635674 | 0.22 |
| Ψ | 51405 | 0.13 | Ψ | 375266 | 0.15 | Ψ | 426671 | 0.15 |
| Ϝ | 349 | 0.00 | Ϛ | 5162 | 0.00 | Ϛ | 5171 | 0.00 |
| Ϛ | 9 | 0.00 | Ϡ | 259 | 0.00 | Ϝ | 505 | 0.00 |
| Ϡ | 4 | 0.00 | Ϝ | 156 | 0.00 | Ϡ | 263 | 0.00 |
| Ϟ | 3 0 | 0.00 0.00 | Ϟ Ϙ | 111 13 | 0.00 0.00 | Ϟ Ϙ | 114 13 | 0.00 0.00 |
Greek corpora contains mathematical texts in Greek, which explains why the rarely used digamma (Ϝ/Ϛ = 6), qoppa (Ϟ/Ϙ = 90), and sampi (Ϡ = 900) letters are included on the table. You can find other interesting differences between Perseus and First1k corpora, like the occurrence of Ρ/Η, K/Π, and Ο/Ι/Ε which are probably explained by the difference of the included text genres in corpora.
Bar chart¶
The next chart will show visually which are the most used letters and the least used letters in the available Ancient Greek corpora.
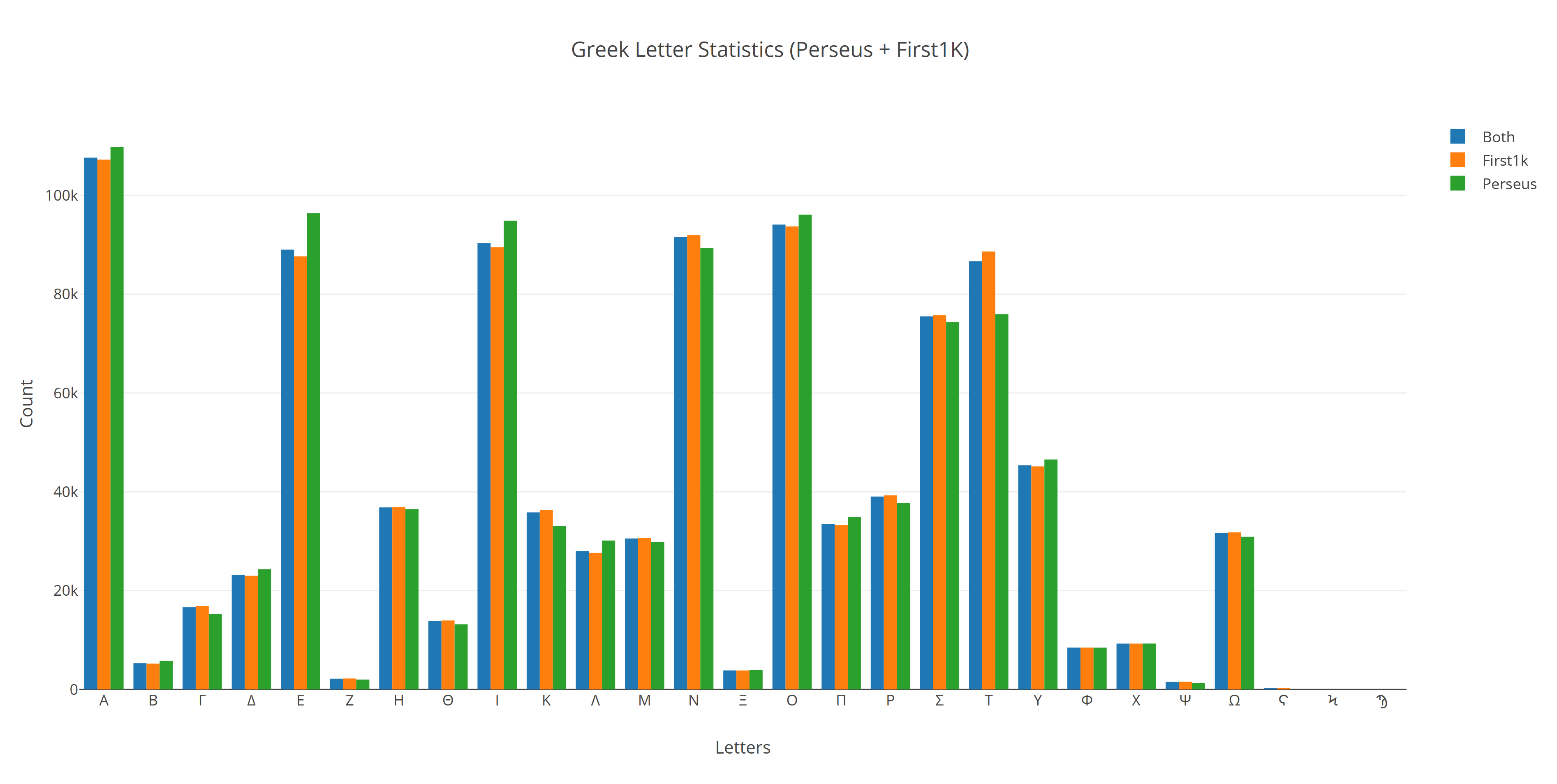
Vowels with N, S, and T consonants pops up as the most used letters. The least used letters are Ζ, Ξ, and Ψ, if the exclusive numerals Ϛ, Ϟ, and Ϡ are not counted.
Optional live chart¶
Uncomment the next part to output a new fresh graph from Plotly:
#import plotly
#plotly.offline.init_notebook_mode(connected=False)
# for the fist time set plotly service credentials, then you can comment
# next line
#plotly.tools.set_credentials_file(username='MarkoManninen', api_key='xyz')
# embed plotly graphs
#plotly.tools.embed("https://plot.ly/~MarkoManninen/8/")
Unique words database¶
Now it is time to collect unique Greek words to the database and show certain specialties of the word statistics. I’m reusing data from the greek_corpora variable that is in the memory already. Running the next code will take a minute or two depending on the processor speed of your computer:
from functions import syllabify, Abnum, greek, vowels
# greek abnum object for calculating isopsephical value of the words
g = Abnum(greek)
# count unique words statistic from the parsed greek corpora
# rather than the plain text file. it would be pretty hefty work to find
# out occurence of the all over 800000 unique words from the text file that
# is over 300 MB big!
unique_word_stats = {}
for item in greek_corpora:
for word, cnt in item['uwords'].items():
if word not in unique_word_stats:
unique_word_stats[word] = 0
unique_word_stats[word] += cnt
# init dataframe
df = DataFrame([[k, v] for k, v in unique_word_stats.items()])
# add column for the occurrence percentage of the word
# lwords3 variable is the length of the all words list
df[2] = df[1].apply(lambda x: round(x*100/lwords3, 2))
# add column for the length of the individual word
df[3] = df[0].apply(lambda x: len(x))
# add isopsephical value column
df[4] = df[0].apply(lambda x: g.value(x))
# add syllabified word column
df[5] = df[0].apply(lambda x: syllabify(x))
# add length of the syllables in word column
df[6] = df[5].apply(lambda x: len(x))
# count vowels in the word as a column
df[7] = df[0].apply(lambda x: sum(list(x.count(c) for c in vowels)))
# count consonants in the word as a column
df[8] = df[0].apply(lambda x: len(x)-sum(list(x.count(c) for c in vowels)))
Store database¶
This is the single most important part of the chapter. I’m saving all simplified unique words as a CSV file that can be used as a database for the riddle solver. After this you may proceed to the riddle solver Jupyter notebook document in interactive mode, if you prefer.
from functions import csv_file_name
# save dataframe to CSV file
df.to_csv(csv_file_name, header=False, index=False, encoding='utf-8')
Noteworth is that stored words are not stems or any base forms of the words but contain words in all possible inflected forms. Due to nature of machine processed texts, one should also be warned about corrupted words and other noise to occur in results. Programming tools are good for extracting interesting content and filtering data that would be impossible for a human to do because of its enormous size. But results still need verification and interpretation. Also, procedures can be fine tuned and developed in many ways.
Most repeated words¶
For a confirmation of the succesful task, I will show the total number of the unique words, and five of the most repeated words in the database:
# import display html helper function
from functions import display_html
# sort and limit words, select columns by index 1, 2, and 3
words = df.sort_values(1, ascending=False).head(n=5).iloc[:,0:3]
# label columns
words.columns = ['Word', 'Count', 'Percent']
# output total number of the words from df object
print("Total records: %s" % len(df))
# index=False to hide index column and output table by using to_html method
display_html(words.to_html(index=False), raw=True)
Total records: 833817
| Word | Count | Percent |
|---|---|---|
| ΚΑΙ | 1781528 | 5.38 |
| ΔΕ | 778589 | 2.35 |
| ΤΟ | 670952 | 2.03 |
| ΤΩΝ | 487015 | 1.47 |
| Η | 483372 | 1.46 |
KAI, the word denoting and-conjuction [20], is well known as the most repeated word in the Ancient Greek. Above statistics says that KAI word takes almost 5.4% of the all words.
This can be explained easily because KAI serves for many fundamental functions in text, such as an indicator of a new chapter or a paragraph, list copulative of two or more items, etc., basicly in a place, where we would use punctuation nowadays. From the other words, Η stands for a paraphrase and ΔΕ for a disconjunction. All these three words characterises Ancient Greek as fundamentally based on logical constructors, one could argue. Maybe even early type of list processing structures have been developed in a form of natural language. It would be an interesting excurse to compare the propositional logic and the list processing features of the Ancient Greek rhetorics to the modern LISP language or similar programming paradigm, but that is definitely beyond the scope of the investigation of this study.
Naturally, articles and particles (ΤΟ, ΤΩΝ) belong to the most repeated words as well. One could use the knowledge of the certain word rate as one of the indicators of the text genre, or even quess the author of the text.
Longest words¶
For a curiosity, let’s also see the longest words in the database:
from functions import HTML
# load result to the temporary variable for later usage
# sort by length, limit to 20 items
l = df.sort_values(3, ascending=False).head(n=20)
# take column index 0, 1, and 3. this is the second way of selecting
# certain columns. see iloc method in the previous example
l = l[[0, 1, 3]]
# label columns
l.columns = ['Word', 'Count', 'Length']
# output table without the index column
HTML(l.to_html(index=False))
A bit later I’m searching exact place of these words from the corpora, but lets first find out, what words have the biggest isopsephical value.
Biggest isopsephical value¶
So, which words have the biggest isopsephical value in the database? We can find it out by sorting words database by the fourth column, that is the isopsephical value of the word.
# sort by the isopsephy column and get the first 20 items
m = df.sort_values(4, ascending=False).head(n=20)
# select columns by indices
m = m[[0, 1, 4]]
# relabel selected columns
m.columns = ['Word', 'Count', 'Isopsephy']
# remove the index column and output table
HTML(m.to_html(index=False))
These are very rare words, as was the case with the longest words too, but as it can be seen, the longest and the biggest isopsephical words are just partly overlapping. Isopsephical value of the word is not depending of the length of the word, but it is depending on the fact, how many times the latter part of the letters in the alphabet occus in the word. In ΛΕΟΝΤΑΤΥΦΛΩΣΩΝΣΚΩΛΩΨΔΕΤΟΥ letters Τ, Φ, Ω, and Σ are repeated several times so that the sum of the alphabetic numerals in the word, i.e. the isopsephical value, is 6865. The value gap between the first and the second word is rather big. Results like these are interesting because they may tell deliberate construction of the words, which I want to detect from the vast sample of coincidental hits.
Before going to the last useful procedure of spotting the location of the words, lets see a special statictic about the frequency of the words.
Word frequency¶
So, I already know that there are certain words repeating very often, for different reasons. But then there are words repeating once or few times only. Thus, it is relevant to ask, how many percent of the whole word base, the least repeated words actually take? For the task I’m using groupby and count methods of the Dataframe object in Pandas.
# length of the words database. taken to a variable to prevent unnecessary
# repeatition in the next for loop
le = len(df)
# group words by occurrence and count grouped items, list the first 10 items
for x, y in df.groupby([1, 2]).count()[:10].T.items():
print("words repeating %s time(s): " % x[0], round(100*y[0]/le, 2), "%")
Output:
words repeating 1 time(s): 44.95 %
words repeating 2 time(s): 15.86 %
words repeating 3 time(s): 7.48 %
words repeating 4 time(s): 4.84 %
words repeating 5 time(s): 3.32 %
words repeating 6 time(s): 2.5 %
words repeating 7 time(s): 1.92 %
words repeating 8 time(s): 1.59 %
words repeating 9 time(s): 1.28 %
words repeating 10 time(s): 1.11 %
Almost 45% of the wodrds in database occurs only once in a corpora. That looks pretty high number which reason I have yet to resolved. Words that repeat 1-4 times fills roughly 70% of the whole corpora.
Detect source texts¶
Stats are nice, but it wouldn’t be so useful, if there was no routine to find out words from corpora, where they actually occur.
The last part of the chapter one is to specify the procedure to find out the exact places of the given words in the corpora. This is going to be useful on the next chapters too. I have provided a search_words_from_corpora function to simplify this task. You may find the code from functions.py and alter it for your use.
Longest words¶
from functions import search_words_from_corpora
# I'm collecting the plain text words from the already instantiated l variable
words = list(y[0] for x, y in l.T.items())
search_words_from_corpora(words, [perseus_dir, first1k_dir])
Output:
+ Aristophanes, Lysistrata (tlg0019.tlg007.perseus-grc2.xml) =>
----- ΣΠΕΡΜΑΓΟΡΑΙΟΛΕΚΙΘΟΛΑΧΑΝΟΠΩΛΙΔΕΣ (1) -----
ὦ ξύμμαχοι γυναῖκες ἐκθεῖτ ἔνδοθεν ὦ σπερμαγοραιολεκιθολαχανοπώλιδες ὦ σκοροδοπανδοκευτριαρτοπώλιδες
+ Aristophanes, Wasps (tlg0019.tlg004.perseus-grc1.xml) =>
----- ΟΡΘΡΟΦΟΙΤΟΣΥΚΟΦΑΝΤΟΔΙΚΟΤΑΛΑΙΠΩΡΩΝ (1) -----
ς ἀκούειν ἡδἔ εἰ καὶ νῦν ἐγὼ τὸν πατέρ ὅτι βούλομαι τούτων ἀπαλλαχθέντα τῶν ὀρθροφοιτοσυκοφαντοδικοταλαιπώρων τρόπων ζῆν βίον γενναῖον ὥσπερ Μόρυχος αἰτίαν ἔχω ταῦτα δρᾶν ξυνωμότης ὢν καὶ φρονῶν
+ Athenaeus, Deipnosophistae (tlg0008.tlg001.perseus-grc3.xml) =>
----- ΠΥΡΒΡΟΜΟΛΕΥΚΕΡΕΒΙΝΘΟΑΚΑΝΘΟΥΜΙΚΤΡΙΤΥΑΔΥ (1) -----
τις ἃ Ζανὸς καλέοντι τρώγματ ἔπειτ ἐπένειμεν ἐνκατακνακομιγὲς πεφρυγμένον πυρβρομολευκερεβινθοακανθουμικτριτυαδυ βρῶμα τοπανταναμικτον ἀμπυκικηροιδηστίχας παρεγίνετο τούτοις
+ Athenaeus, TheDeipnosophists (tlg0008.tlg001.perseus-grc4.xml) =>
----- ΠΥΡΟΒΡΟΜΟΛΕΥΚΕΡΕΒΙΝΘΟΑΚΑΝΘΙΔΟΜΙΚΡΙΤΡΙΑΔΥ (1) -----
ἐπεί γ ἐπένειμεν ἐγκατακνακομιγὲς πεφρυγμένον πυροβρομολευκερεβινθοακανθιδομικριτριαδυ βρωματοπαντανάμικτον ἄμπυκι καριδίᾳ στιχὰς παρεγίνετο τούτοις σταιτινοκογχομαγὴς
+ Plato, Laws (tlg0059.tlg034.perseus-grc2.xml) =>
----- ΤΕΤΤΑΡΑΚΟΝΤΑΚΑΙΠΕΝΤΑΚΙΣΧΙΛΙΟΣΤΟΝ (1) -----
πεφευγότος ἀμφοτέρωθεν πρός τε ἀνδρῶν καὶ πρὸς γυναικῶν κληρονόμον εἰς τὸν οἶκον τοῦτον τῇ πόλει τετταρακοντακαιπεντακισχιλιοστὸν καταστῆσαι βουλευομένους μετὰ νομοφυλάκων καὶ ἱερέων διανοηθέντας τρόπῳ καὶ λόγῳ τοιῷδε ὡς οὐδεὶς
+ Plato, Republic (tlg0059.tlg030.perseus-grc2.xml) =>
----- ΕΝΝΕΑΚΑΙΕΙΚΟΣΙΚΑΙΕΠΤΑΚΟΣΙΟΠΛΑΣΙΑΚΙΣ (1) -----
τοῦ τυράννου ἀφεστηκότα λέγῃ ὅσον ἀφέστηκεν ἐννεακαιεικοσικαιεπτακοσιοπλασιάκις ἥδιον αὐτὸν ζῶντα εὑρήσει τελειωθείσῃ τῇ πολλαπλασιώσει τὸν δὲ τύραννον ἀνιαρότερον τῇ αὐτῇ ταύτῃ
+ AlexanderOfAphrodisias, InAristotelisMetaphysicaCommentaria (tlg0732.tlg004.opp-grc1.xml) =>
----- ΟΥΝΙΚΑΝΩΣΠΕΡΙΑΥΤΩΝΗΜΙΝΕΝΤΟΙΣΠΕΡΙ (1) -----
οιησά αενο τ ιστεύσομεν ρ Φ τεθεώρηται μὲν οὐνὶκανῶςπερὶαὐτῶνἡμῖνἐντοῖςπερὶ φύσεως ἰκαὶἱκανῶς φησί περὶτῶ ν ἀρχῶν τῶν φυσικῶν ἐν τοῖς περὶ φύσεως
+ AlexanderOfAphrodisias, InAristotelisTopicorumLibrosOctoCommentaria (tlg0732.tlg006.opp-grc1.xml) =>
----- ΟΤΙΤΟΥΜΗΔΙΑΠΡΟΤΕΡΩΝΟΡΙΖΕΣΘΑΙΤΡΕΙΣ (1) -----
Τοῦ δὲ μὴ ἐκπροτέρων τρεῖς εἰσι τρόποι Ὅτιτοῦμὴδιὰπροτέρωνὁρίζεσθαιτρεῖς εἰσι τρόποι πρῶτοςμὲν εἰ διὰ τοῦ ἀντικειμένου τὸ ἀντικείμενον ὥρισται ἅμ γὰρ τῇ φύσει τὰ ἀντικείμ
+ ApolloniusDyscolus, DeAdverbiis (tlg0082.tlg002.1st1K-grc1.xml) =>
----- ΠΑΡΕΓΕΝΟΜΕΝΟΜΕΝΟΣΗΝΚΑΙΕΤΙΕΚΤΗΣΛΕΣΒΟΥΟΥΦΑΜΕΝ (1) -----
τῆϲ Λέϲβου τηϲ εκ εκ Λεϲβο παρεγενόμην καὶ ἔτι οῦ φαμεν παρεγενομενομενοϲηνκαιετιεκτηϲλεϲβουουφαμεν Α εκ τηϲ Λεϲβου ἔτι οὐ
+ ApolloniusDyscolus, DeConstructione (tlg0082.tlg004.1st1K-grc1.xml) =>
----- ΚΑΙΤΟΝΑΡΙΣΤΑΡΧΟΝΑΣΜΕΝΩΣΤΗΝΓΡΑΦΗΝΤΟΥ (1) -----
ἠλογῆϲθαι φαϲ δὲ καίτὸνἈρίϲταρχονἀϲμένωϲτὴνγραφὴντοῦ Δικαιάρχουπαραδέξαϲθαι ἐνγὰρἁπάϲαιϲ ν τὸ εὲῇ ἐν πατρίδι γαί ὑπολαβόντα τὸ ἑαυτῆϲ νοεὶϲθαι ἐκ το
----- ΑΡΣΕΝΙΚΩΝΟΝΟΜΑΤΩΝΣΤΟΙΧΕΙΑΕΣΤΙΠΕΝΤΕ (1) -----
τ τὸ ᾶ τελικόν ἐϲτιν κτλ Τελικὰ ἀρϲενικῶνὸνομάτωνϲτοιχεῖάἐϲτιπέντε θηλυκῶνδὲ ὸκτώ ᾶη ωνξΒ ψ οὐδετέ ρων δὲ ἐ ῦ εραίαν
----- ΑΡΙΣΤΑΡΧΟΣΚΑΙΟΙΑΠΟΤΗΣΣΧΟΛΗΣΦΑΣΙΝ (1) -----
αὐτῇ Ϲ θϲτή εϲι Β καθότ Ϲ καθ ϲ ὁ Ἀρίϲταρχοϲκαὶοίἀπὸτῆϲϲχολῆϲφαϲιν οὶϲ οὐ ϲυγκαταθετέον ε φαϲίν οὐκ ὀρθῶϲ
+ Artemidorus, Onirocriticon (tlg0553.tlg001.1st1K-grc1.xml) =>
----- ΑΥΤΟΜΑΤΟΙΔΕΟΙΘΕΟΙΑΠΑΛΛΑΣΣΟΜΕΝΟΙ (1) -----
ς μεγάλας σημαίνει οἱ γὰρ ἐν μεγάλαις συμφοραῖς γενόμενοι καὶ τῆς πρὸς θεούς εὐσεβείας ἀφίστανται αὐτόματοιδέοἱθεοὶἀπαλλασσόμενοι καὶ τὰ ἀγάλμιατα αὐτῶν συμπίπτοντα θάνατον τῷ ἰδόντι ἤ τινι τῶν αὐτοῦ προαγορεύει θεο
+ JoannesPhiloponus, InAristotetelisMeteorologicorumLibrumPrimumCommentarium (tlg4015.tlg005.opp-grc1.xml) =>
----- ΛΛΗΣΤΗΣΑΝΩΘΕΝΘΕΡΜΟΤΗΤΟΣΑΤΜΙΔΟΥΜΕΝΟΝΦΕΡΕΤΑΙ (1) -----
νῦν μενούσης ἀμεταβλήτου τὸ οὖν περὶ τὴν γῆν ὑγρόν φησίν ὑπὸ τῶν ἀκτίνων καὶ ὑπὸ τῆς ὰ λληςτῆςἄνωθενθερμότητοςἀτμιδούμενονφέρεται ἄνω πῶς μὲν ἡ ἐκ τῶν ἀκτίνων γίνεται θερμότης ἐδίδαξεν ὅτι ὁ ε ναπο λαμβαν
----- ΔΥΝΑΤΟΝΔΕΤΟΑΙΤΙΑΙΗΣΓΕΝΕΣΕΩΣΚΑΙΤΗΣΦΘΟΡΑΣ (1) -----
λὴ ἀνάλογόν ἐστι γενέσει ἡ δὲ τοὔμπαλιν τῶν κουφοτέρων εἰς τὰ βαρότεραφθορᾷ δυνατὸνδὲτὸαἰτίαιῆςγενέσεωςκαὶτῆςφθορᾶς διὰ τὸ ἄρθρον μὴ καθολικῶς ἀκούειν πάσης γενέσεως καὶ φθορᾶς ἀλλὰ ὑετοῦ χιόν
+ Libanius, Epistulae1-839 (tlg2200.tlg001.opp-grc1.xml) =>
----- ΕΜΟΥΟΙΑΠΕΦΕΥΓΑΧΕΙΡΑΣΛΥΠΗΣΑΣΜΕΝΟΥΔΕΝΑΟΥΔΕΝ (1) -----
δον κατηφῆ καὶ συνεοταλμἐνον καὶ δάκρυα πρὸ τῶν λόγωνἀφεὶς ἐγὼ μόλις τὰς τῶν παθόντων ἐμοῦόιαπέφευγαχεῖραςλυπήσαςμὲνοὐδέναοὐδέν ἡνίκα ἐξῆν μικρο δὲ διασπασθείς καὶ προσετίθει φυγὴν ἀδελφοῦ καὶ γένους ὅλου πλάνην καὶ γῆν ἄσπ
----- ΚΑΙΙΚΕΛΗΧΡΥΣΗΑΦΡΟΔΙΤΗΚΑΙΟΙΣΕΚΟΣΜΗΣΕ (1) -----
ε γονεῦσιν αὐτῆς καὶ σοὶ συνη σθην τοῖς μέν οἕαν ἔφυσαν σοὶ δέ οἴαν ἔχεις Δήλῳ δή ποτε τοῖον καὶἰκέληχρυσῇἈφροδίτῃκαὶοἷςἐκόσμησε γυναῖκας Ὅμηρος πάντα ἂν δέξαιτο ἀναμιμν
----- ΚΑΝΤΩΝΕΠΙΤΑΙΣΔΥΝΑΜΕΣΙΠΑΡΑΒΑΙΝΗ (1) -----
ὅτι ὦ βασιλεῦ τῶν ἀδικούντων οὐδένα οὺόὲν ἀξίωμα ῥύσεται ἀλλὰ κἂν τῶν δικαζόντων τις κἂντῶνἐπὶταἱςδυνάμεσιπαραβαίνη του ςνο μους οὐκἀνέζομαιἀμελεῖσθαι τα
+ Libanius, OratioI (tlg2200.tlg00401.opp-grc1.xml) =>
----- ΗΔΙΚΗΜΕΝΟΝΔΕΑΠΕΡΡΙΜΜΕΝΟΝΠΕΡΙΟΡΑΣ (1) -----
τέ τῶν μὲν ἐξέβαλες τὰ δὲοὐΙδίδως ἀλλ ὁ μὲν ἠπατηκὼς τρυφᾷ τὸν ἠδικημένονδὲἀπερριμμένονπεριορᾷς τοι αυ τα με ν προ ς το ε δος πο ρ
+ Suda, SuidaeLexicon (tlg9010.tlg001.1st1K-grc1.xml) =>
----- ΟΡΘΟΦΟΙΤΟΣΥΚΟΦΑΝΤΟΔΙΚΟΤΑΛΑΙΠΩΡΩΝ (2) -----
Ὀρθοφοιτοϲυκοφαντοδικοταλαιπώρων Ἀριϲτοφάνηϲ ὁτιὴ βούλομαι τούτων ἀπαλλαχθέντα τῶν ὀρθοφοιτοϲυκοφα
οδικοταλαιπώρων Ἀριϲτοφάνηϲ ὁτιὴ βούλομαι τούτων ἀπαλλαχθέντα τῶν ὀρθοφοιτοϲυκοφαντοδικοταλαιπώρων τρόπων ζῆν βίον γενναῖον ὥϲπερ Μόρυχοϲ αἰτίαν ἔχων ταῦτα δρᾶν
----- ΣΠΕΡΜΑΓΟΡΑΙΟΛΕΚΙΘΟΛΑΧΑΝΟΠΩΛΙΔΕΣ (1) -----
Ὦ ϲπερμαγοραιολεκιθολαχανοπώλιδεϲ ὦ ϲκοροδοπανδοκευτριαρτοπώλιδεϲ οὐκ ἐξέλκετ οὐ παιήϲετ οὐκ
For a small explanation: Aristophanes was a Greek comic playwright and a word expert of a kind. Mathematical texts are also filled with long compoud words for fractions for example.
Highest isopsephy¶
# I'm collecting the plain text words from the already instantiated m variable
words = list(y[0] for x, y in m.T.items())
search_words_from_corpora(words, [perseus_dir, first1k_dir])
Output:
+ Appian, TheCivilWars (tlg0551.tlg017.perseus-grc2.xml) =>
----- ΣΥΝΥΠΟΧΩΡΟΥΝΤΩΝ (1) -----
καὶ ἡ σύνταξις ἤδη παρελέλυτο ὀξύτερον ὑπεχώρουν καί τῶν ἐπιτεταγμένων σφίσι
δευτέρων καὶ τρίτων συνυποχωρούντων μισγόμενοι πάντες ἀλλήλοις ἀκόσμως
ἐθλίβοντο ὑπὸ σφῶν καὶ τῶν πολεμίων ἀπαύστως αὐτοῖς ἐπικειμένων
+ Aristophanes, Wasps (tlg0019.tlg004.perseus-grc1.xml) =>
----- ΟΡΘΡΟΦΟΙΤΟΣΥΚΟΦΑΝΤΟΔΙΚΟΤΑΛΑΙΠΩΡΩΝ (1) -----
ς ἀκούειν ἡδἔ εἰ καὶ νῦν ἐγὼ τὸν πατέρ ὅτι βούλομαι τούτων ἀπαλλαχθέντα τῶν
ὀρθροφοιτοσυκοφαντοδικοταλαιπώρων τρόπων ζῆν βίον γενναῖον ὥσπερ Μόρυχος
αἰτίαν ἔχω ταῦτα δρᾶν ξυνωμότης ὢν καὶ φρονῶν
+ Athenaeus, Deipnosophistae (tlg0008.tlg001.perseus-grc3.xml) =>
----- ΒΡΥΣΩΝΟΘΡΑΣΥΜΑΧΕΙΟΛΗΨΙΚΕΡΜΑΤΩΝ (1) -----
τῶν ἐξ Ἀκαδημίας τις ὑπὸ Πλάτωνα καὶ Βρυσωνοθρασυμαχειοληψικερμάτων πληγεὶς
ἀνάγκῃ ληψολιγομίσθῳ τέχνῃ σ
+ Athenaeus, TheDeipnosophists (tlg0008.tlg001.perseus-grc4.xml) =>
----- ΒΡΥΣΩΝΟΘΡΑΣΥΜΑΧΕΙΟΛΗΨΙΚΕΡΜΑΤΩΝ (1) -----
Βρυσωνοθρασυμαχειοληψικερμάτων πληγεὶς ἀνάγκῃ ληψιλογομίσθῳ τέχνῃ
+ AlexanderOfAphrodisias, InAristotelisMetaphysicaCommentaria (tlg0732.tlg004.opp-grc1.xml) =>
----- ΟΥΝΙΚΑΝΩΣΠΕΡΙΑΥΤΩΝΗΜΙΝΕΝΤΟΙΣΠΕΡΙ (1) -----
οιησά αενο τ ιστεύσομεν ρ Φ τεθεώρηται μὲν οὐνὶκανῶςπερὶαὐτῶνἡμῖνἐντοῖςπερὶ
φύσεως ἰκαὶἱκανῶς φησί περὶτῶ ν ἀρχῶν τῶν φυσικῶν ἐν τοῖς περὶ φύσεως
+ ApolloniusDyscolus, DeConstructione (tlg0082.tlg004.1st1K-grc1.xml) =>
----- ΚΑΙΤΟΝΑΡΙΣΤΑΡΧΟΝΑΣΜΕΝΩΣΤΗΝΓΡΑΦΗΝΤΟΥ (1) -----
ἠλογῆϲθαι φαϲ δὲ καίτὸνἈρίϲταρχονἀϲμένωϲτὴνγραφὴντοῦ Δικαιάρχουπαραδέξαϲθαι
ἐνγὰρἁπάϲαιϲ ν τὸ εὲῇ ἐν πατρίδι γαί ὑπολαβόντα τὸ ἑαυτῆϲ νοεὶϲθαι ἐκ το
----- ΑΡΣΕΝΙΚΩΝΟΝΟΜΑΤΩΝΣΤΟΙΧΕΙΑΕΣΤΙΠΕΝΤΕ (1) -----
τ τὸ ᾶ τελικόν ἐϲτιν κτλ Τελικὰ ἀρϲενικῶνὸνομάτωνϲτοιχεῖάἐϲτιπέντε
θηλυκῶνδὲ ὸκτώ ᾶη ωνξΒ ψ οὐδετέ ρων δὲ ἐ ῦ εραίαν
----- ΑΡΙΣΤΑΡΧΟΣΚΑΙΟΙΑΠΟΤΗΣΣΧΟΛΗΣΦΑΣΙΝ (1) -----
αὐτῇ Ϲ θϲτή εϲι Β καθότ Ϲ καθ ϲ ὁ Ἀρίϲταρχοϲκαὶοίἀπὸτῆϲϲχολῆϲφαϲιν οὶϲ οὐ
ϲυγκαταθετέον ε φαϲίν οὐκ ὀρθῶϲ
+ ApolloniusDyscolus, DePronominibus (tlg0082.tlg001.1st1K-grc1.xml) =>
----- ΩΡΙΣΜΕΝΩΝΠΡΟΣΩΠΩΝ (1) -----
ι καὶ τὰ ἀναφερύμενα γνῶϲιν ἐπαγγέλλεται προῦφεϲτῶϲαν ὅ ἐϲτι πάλιν πρόϲωπον
ὡριϲμένον ὀρθῶϲ ἄρα ὡριϲμένωνπροϲώπων παραϲτατικὴ ἡ ἀντωνυμία
+ Aristotle, MagnaMoralia (tlg0086.tlg022.1st1K-grc1.xml) =>
----- ΤΩΟΡΘΩΕΚΑΣΤΑΘΕΩΡΩΝ (1) -----
καὶ μὴ διεψεῦσθαι τῷ λόγῳ ἔστιν δὲ καὶ ὁ φρόνιμός τοιοῦτος ὁτῷ λόγῳ
τῷὀρθῷἕκασταθεωρῶν πότερον δ ἐνδέχεταιτὸν φρόνιμον ἀκρατῆ εἶναι ἢ οὔ
ἀπορήσειε γὰρ ἄν τις τὰ εἰρημένα ἐὰν δὲ πα ρ
+ ChroniconPaschale, ChroniconPaschale (tlg2371.tlg001.opp-grc1.xml) =>
----- ΟΠΡΩΤΟΣΑΝΘΡΩΠΩΝΥΠΟΔΕΙΞΑΣ (1) -----
δείξας οὐρανοδρομεῖν όπρῶτοςἀνθρώπωνὑποδείξας ἀγγέλων καὶ ἀνθρώπων μίαν
ὁδόν ὁ τὴν γῆν λαχὼν οἰκητηιριον καὶ τὸν οὐρανὸν
+ EvagriusScholasticus, HistoriaEcclesiastica (tlg2733.tlg001.1st1K-grc1.xml) =>
----- ΓΛΩΣΣΟΤΟΜΗΘΕΝΤΩΝΧΡΙΣΤΙΑΝΩΝ (1) -----
ιδ Περὶ Ὀνωρίχου τοῦ Βανδίλων ἄρχοντος καὶ τῶν γλωσσοτομηθέντωνΧριστιανῶν
παῤ αὐτοῦ ιε Περὶ Καβαώνου
----- ΕΠΙΣΚΟΠΩΚΩΝΣΤΑΝΤΙΝΟΥΠΟΛΕΩΣ (1) -----
ἐστιν ἐν τούτοις Ἐπιστολὴ ἤτοι δέησις ἀποσταλεῖσα Ἀκακίῳ
ἐπισκόπῳΚωνσταντινουπόλεως παρὰ τῶν τῆς Ἀσίας ἐπισκόπων Ἀκακίῳ τῷ ἁγιωτάτῳ
καὶ ὁσιωτάτῳ πατριάρχῃ
+ JoannesPhiloponus, InAristotetelisMeteorologicorumLibrumPrimumCommentarium (tlg4015.tlg005.opp-grc1.xml) =>
----- ΛΛΗΣΤΗΣΑΝΩΘΕΝΘΕΡΜΟΤΗΤΟΣΑΤΜΙΔΟΥΜΕΝΟΝΦΕΡΕΤΑΙ (1) -----
νῦν μενούσης ἀμεταβλήτου τὸ οὖν περὶ τὴν γῆν ὑγρόν φησίν ὑπὸ τῶν ἀκτίνων καὶ
ὑπὸ τῆς ὰ λληςτῆςἄνωθενθερμότητοςἀτμιδούμενονφέρεται ἄνω πῶς μὲν ἡ ἐκ τῶν
ἀκτίνων γίνεται θερμότης ἐδίδαξεν ὅτι ὁ ε ναπο λαμβαν
----- ΔΥΝΑΤΟΝΔΕΤΟΑΙΤΙΑΙΗΣΓΕΝΕΣΕΩΣΚΑΙΤΗΣΦΘΟΡΑΣ (1) -----
λὴ ἀνάλογόν ἐστι γενέσει ἡ δὲ τοὔμπαλιν τῶν κουφοτέρων εἰς τὰ βαρότεραφθορᾷ
δυνατὸνδὲτὸαἰτίαιῆςγενέσεωςκαὶτῆςφθορᾶς διὰ τὸ ἄρθρον μὴ καθολικῶς ἀκούειν
πάσης γενέσεως καὶ φθορᾶς ἀλλὰ ὑετοῦ χιόν
+ Libanius, Epistulae1-839 (tlg2200.tlg001.opp-grc1.xml) =>
----- ΕΜΟΥΟΙΑΠΕΦΕΥΓΑΧΕΙΡΑΣΛΥΠΗΣΑΣΜΕΝΟΥΔΕΝΑΟΥΔΕΝ (1) -----
δον κατηφῆ καὶ συνεοταλμἐνον καὶ δάκρυα πρὸ τῶν λόγωνἀφεὶς ἐγὼ μόλις τὰς
τῶν παθόντων ἐμοῦόιαπέφευγαχεῖραςλυπήσαςμὲνοὐδέναοὐδέν ἡνίκα ἐξῆν μικρο δὲ
διασπασθείς καὶ προσετίθει φυγὴν ἀδελφοῦ καὶ γένους ὅλου πλάνην καὶ γῆν ἄσπ
+ PhiloJudaeus, DeVitaMosisLibI‑Ii (tlg0018.tlg022.opp-grc1.xml) =>
----- ΨΥΧΟΓΟΝΙΜΩΤΑΤΩΝ (1) -----
ν ἀπετελέσθησαν αἱ σωματικαὶ ποιότητες ἐφεὶς τῷ Μωυσέως ἀδελφῷ τὰς δ ἴσας
ἐξ ἀέρος καὶ πυρὸς τῶν ψυχογονιμωτάτων μόνῳ Μωυσεῖ μίαν δὲ κοινὴν ἀμφοτέροις
ἑβδόμην ἐπιτρέπει τρεῖς δὲ τὰς ἄλλας εἰς συμπ
+ Porphyrius, VitaPythagorae (tlg2034.tlg002.1st1K-grc1.xml) =>
----- ΤΟΥΤΟΥΣΛΕΓΟΝΤΕΣΩΣΠΡΟΣΤΗΝ (1) -----
οι τὰς δυνάμεις τῶν στοιχείων καὶ αὐτὰ ταῦτα βουλόμενοι παραδοῦναι
παρεγένοντο ἐπὶ τοὺςχαρακτῆρας τούτουςλέγοντεςὡςπρὸςτὴν πρώτην διδασκαλίαν
στοιχεῖα εἶναι ὕστερον μέντοι διδάσκου σιν ὅτι οὐχ οὗτοι στοιχεῖά εἰσιν οἱ
χαρ
+ Suda, SuidaeLexicon (tlg9010.tlg001.1st1K-grc1.xml) =>
----- ΟΡΘΟΦΟΙΤΟΣΥΚΟΦΑΝΤΟΔΙΚΟΤΑΛΑΙΠΩΡΩΝ (2) -----
Ὀρθοφοιτοϲυκοφαντοδικοταλαιπώρων Ἀριϲτοφάνηϲ ὁτιὴ βούλομαι τούτων
ἀπαλλαχθέντα τῶν ὀρθοφοιτοϲυκοφα
οδικοταλαιπώρων Ἀριϲτοφάνηϲ ὁτιὴ βούλομαι τούτων ἀπαλλαχθέντα τῶν
ὀρθοφοιτοϲυκοφαντοδικοταλαιπώρων τρόπων ζῆν βίον γενναῖον ὥϲπερ Μόρυχοϲ
αἰτίαν ἔχων ταῦτα δρᾶν
----- ΚΩΔΩΝΟΦΑΛΑΡΑΧΡΩΜΕΝΟΥΣ (1) -----
μετήνεκται οὕτω ψοφοῦνταϲ ψοφοῦντεϲ Κωδωνοφαλαραχρωμένουϲ αὐτὰϲ Κώδων
Σοφοκλῆϲ Τυρρηνικῆϲ
+ ValeriusBabrius, FabulaeAesopeae (tlg0614.tlg001.1st1K-grc2.xml) =>
----- ΛΕΟΝΤΑΤΥΦΛΩΣΩΝΣΚΩΛΩΨΔΕΤΟΥ (1) -----
τι ποιήσω καὶ εἰπὼν ἐπέβαλε τοιχοδεχειρασεπεβαλετον λεοντατυφλωσωνσκωλωψδετου
τωυπονυχα υποδυνα κεκαδαιμωσδουστη σαρκοσεισδυσησηνυσε θ ποιων
So, that’s all for the Greek corpora processing and basic statistics. One could further investigate, categorize, and compare individual texts, but for me it is time to jump to the second big task, that is defining procedures for the riddle solver.
| [1] | https://en.wikipedia.org/wiki/Sibylline_Oracles |
| [2] | https://en.wikipedia.org/wiki/Sibylline_Books |
| [3] | https://books.google.fi/books?id=TNdeolWctsQC |
| [4] | https://books.google.fi/books?id=Zqh8ZQZqnWYC |
| [5] | http://python.org |
| [6] | https://github.com/markomanninen/grcriddles/blob/master/functions.py |
| [7] | https://jupyter.org |
| [8] | https://github.com/markomanninen/grcriddles/blob/master/Processing%20Greek%20corpora%20for%20the%20isopsehical%20riddle%20solver.ipynb |
| [9] | https://github.com/markomanninen/grcriddles/blob/master/Isopsephical%20riddles%20in%20the%20Greek%20Pseudo%20Sibylline%20hexameter%20poetry.ipynb |
| [10] | https://github.com/markomanninen/grcriddles/blob/master/ |
| [11] | https://www.python.org/shell/ |
| [12] | https://github.com/tqdm/tqdm |
| [13] | http://www.perseus.tufts.edu/hopper/opensource/download |
| [14] | http://opengreekandlatin.github.io/First1KGreek/ |
| [15] | https://github.com/markomanninen/abnum3 |
| [16] | https://github.com/jtauber/greek-accentuation |
| [17] | http://pandas.pydata.org |
| [18] | https://plot.ly |
| [19] | https://www.nltk.org/ |
| [20] | https://github.com/cltk/cltk |
| [21] | https://en.wikipedia.org/wiki/Greek_alphabet#Greek_in_Unicode |
| [22] | http://www.perseus.tufts.edu/hopper/text?doc=Perseus:text:1999.04.0057:entry=kai/1 |